
Session Date: 2026-03-28
Project: Research Analysis & Knowledge Curation
Focus: Platform velocity and knowledge decay in developer tooling guidance
Session Type: Research & Analysis
Platform Docs Ship Faster Than Blogs Can Follow
In most software ecosystems, a developer’s “here’s my setup” post from eighteen months ago is still roughly applicable. The fundamentals of git, bash, or Vim do not ship breaking changes on a quarterly cadence. A thoughtful blog post about configuring your shell environment in 2024 is probably still useful in 2026.
Claude Code is not that kind of tool.
This session audited Robert Marshall’s article Turning Claude Code into a Development Powerhouse — a firsthand optimization guide that represented industry-leading development practices and a wealth of subject matter expertise when it was published on August 21st, 2025. But standard composite checks for ecosystem fit and performance quality gave it a 3.8/10 score as of today, March 28th, 2026. LLM-backed coding assistants and the ecosystems that surround them have had roughly 7 months to ship new features and tools since it was written, and the gap between what the article recommends and what the platform currently supports is now large enough to produce meaningfully worse outcomes for readers who follow it. The largest gap is not a factual error — it is an entire automation layer the article does not know exists.
That rate of decay is faster than the hallucination research field. Even canonical academic research on LLM hallucination — written by credible authors, carefully cited — scores 5.6/10 against current practice after less than two years. Neural network papers have an 18–24 month half-life on specific methods. Developer platform guidance for an actively-shipped CLI tool has closer to a 12-month half-life — and the acceleration is not slowing.
What the Audit Measured
Five dimensions, each scored 0–10:
| Dimension | Score | What It Captures |
|---|---|---|
| Factual Accuracy | 6 | Are the specific claims still correct? |
| Relevance | 7 | Does the problem framing still apply? |
| Staleness | 3 | How much of the recommended surface has been superseded? |
| Completeness | 2 | Does it cover the platform’s actual capability surface? |
| Workflow Coverage | 3 | Does it reflect how practitioners actually configure Claude Code today? |
| Composite | 3.8 |
Audited against official Claude Code documentation · Reference date March 28, 2026
The high relevance score (7) and low completeness score (2) tell the real story: the problem the article identifies — context loss producing generic, project-unaware outputs — is still the right problem. The solutions it recommends address roughly 5% of the platform’s current answer to that problem.
What the Article Actually Recommends
Marshall’s setup rests on four MCP integrations:
- Context7 — real-time third-party library documentation via SSE transport
- Serena — semantic code search, structure-aware rather than text-matching
- Sequential Thinking — structured reasoning as a decision scaffold for complex problems
- WisprFlow — voice dictation layer for prompt input
These are wrapped by a custom /go slash command that reads a claude.md file and primes Claude with project context before execution. The workflow guidance emphasizes planning mode before coding, and breaking requirements into manually defined sections.
The performance claim is a 60–70% reduction in time on complex features, with an OAuth implementation cited as a concrete example (30 minutes reduced to 8).
The recommendations are coherent as a first-month setup. They are approximately what a thoughtful developer arrives at after a few weeks of serious use. The problem is that several months of continued use, and the platform’s own documentation, point to a substantially different and more powerful configuration surface.
What Changed in Under Two Years
The Hooks System Shipped — The Article Has No Awareness of It
This is the most significant gap. The article’s core thesis is that Claude produces generic outputs without project context, and the solution is injecting context via MCP and CLAUDE.md. That framing was reasonable in early 2025. By March 2026, the platform has a full automation and enforcement layer that changes the architecture of the problem entirely.
Claude Code’s hooks system supports 20+ lifecycle events — including PreToolUse, PostToolUse, SessionStart, Stop, TaskCreated, and WorktreeCreate — and can:
- Block tool calls before execution (exit 2 on
PreToolUse) to enforce architectural constraints - Modify tool input or replace MCP tool output
- Spawn HTTP requests to external validation endpoints
- Launch full subagents with tool access to verify complex conditions
The article’s /go command manually stitches context together at session start. Hooks enforce context and behavior automatically, throughout the session, without requiring a prompt ritual. An article claiming to make Claude Code a “development powerhouse” that does not mention hooks is like a CI/CD guide that does not mention pipelines.
Auto Memory Superseded the Manual claude.md Ritual
The article’s primary memory mechanism is a manually-maintained claude.md file that the /go command reads at session start. This is directionally correct as an early workaround. It has since been superseded by native auto memory.
Claude Code now automatically accumulates project learnings — build commands, debugging patterns, architectural preferences, recurring corrections — in ~/.claude/projects/<project>/memory/MEMORY.md. This addresses the article’s stated problem (context loss between sessions) without requiring a manual maintenance ritual or a custom slash command to inject it. The article describes a workaround for a problem that the platform now solves natively.
Beyond auto memory, the CLAUDE.md architecture the article alludes to is substantially richer than described:
- Scope hierarchy: managed policy (
/Library/Application Support/ClaudeCode/CLAUDE.md) → project (./CLAUDE.md) → user (~/.claude/CLAUDE.md) — not a single flat file .claude/rules/directory: path-scoped instruction files that only load when Claude works with matching file patterns, reducing context noise@imports: compose instruction sets from multiple files/init: auto-generate a starter CLAUDE.md by analyzing the codebase/memory: browse and edit all loaded memory files in-session
The Sequential Thinking MCP Is Now Redundant
The article recommends the Sequential Thinking MCP to handle complex reasoning tasks — “decision tree mapping” for multi-step problems. By March 2026, this is solved natively.
Extended thinking (effortLevel: "high") is built into Opus 4.6 and Sonnet 4.6. The /effort command adjusts reasoning depth mid-session. Using a third-party MCP for structured reasoning adds a network dependency and maintenance burden in exchange for a capability the model already has. This is the clearest case in the article of recommending an external solution to a problem that has since been absorbed into the platform itself.
The pattern: MCP is the right answer for genuinely external context (live library docs, company knowledge bases, external APIs). It is the wrong answer for reasoning depth, which is a model-level property.
MCP Configuration Has a Canonical Team-Scale Pattern the Article Ignores
The article’s MCP setup is CLI-first and per-developer: claude mcp add commands executed individually. This works for a solo setup but does not scale.
The current canonical pattern is .mcp.json committed to the project repository, with enabledMcpjsonServers trust controls in settings.json. The whole team gets the same MCP servers without per-developer setup. The article’s approach produces configuration drift across collaborators; the canonical approach makes MCP configuration a first-class part of the project.
The article also uses --transport sse for Context7. Current best practice is --transport http (streamable HTTP). SSE transport is still supported but is documented as a legacy fallback.
Additionally, Anthropic now maintains an official MCP registry at api.anthropic.com/mcp-registry/v0/servers — a curated, discoverable source of verified integrations covering Jira, Slack, Google Drive, GitHub, and more. The article treats MCP discovery as a manual search problem; a registry-first approach now exists.
The Settings System and Permissions Model Are Completely Absent
The article has no mention of .claude/settings.json — the project-scope configuration file that is committed to git and shared with the team. Current practitioners use this to encode:
permissions.allow / permissions.deny— tool access without per-session promptingeffortLevel— reasoning depth default across sessionsmodel— model pinning for reproducibilityautoMode— execution permission leveldisableAllHooks,enableAllProjectMcpServers,enabledMcpjsonServers— trust and automation controls
A team that follows the article’s setup is prompting for permission on every tool call and re-specifying preferences every session. A team that uses settings.json encodes those decisions once, in version control, where they persist across collaborators and CI runs.
Observability Is Absent
The article’s only performance measurement is self-reported (“felt 60–70% faster”). There is no methodology, no baseline, and no breakdown of which component produced which improvement.
The cost of that gap is not hypothetical:
- AI-generated code contains 1.7x more defects than human-written code.1
- Incidents per PR up 23.5% as AI adoption has scaled.2
- Time spent “re-working the slop”.3
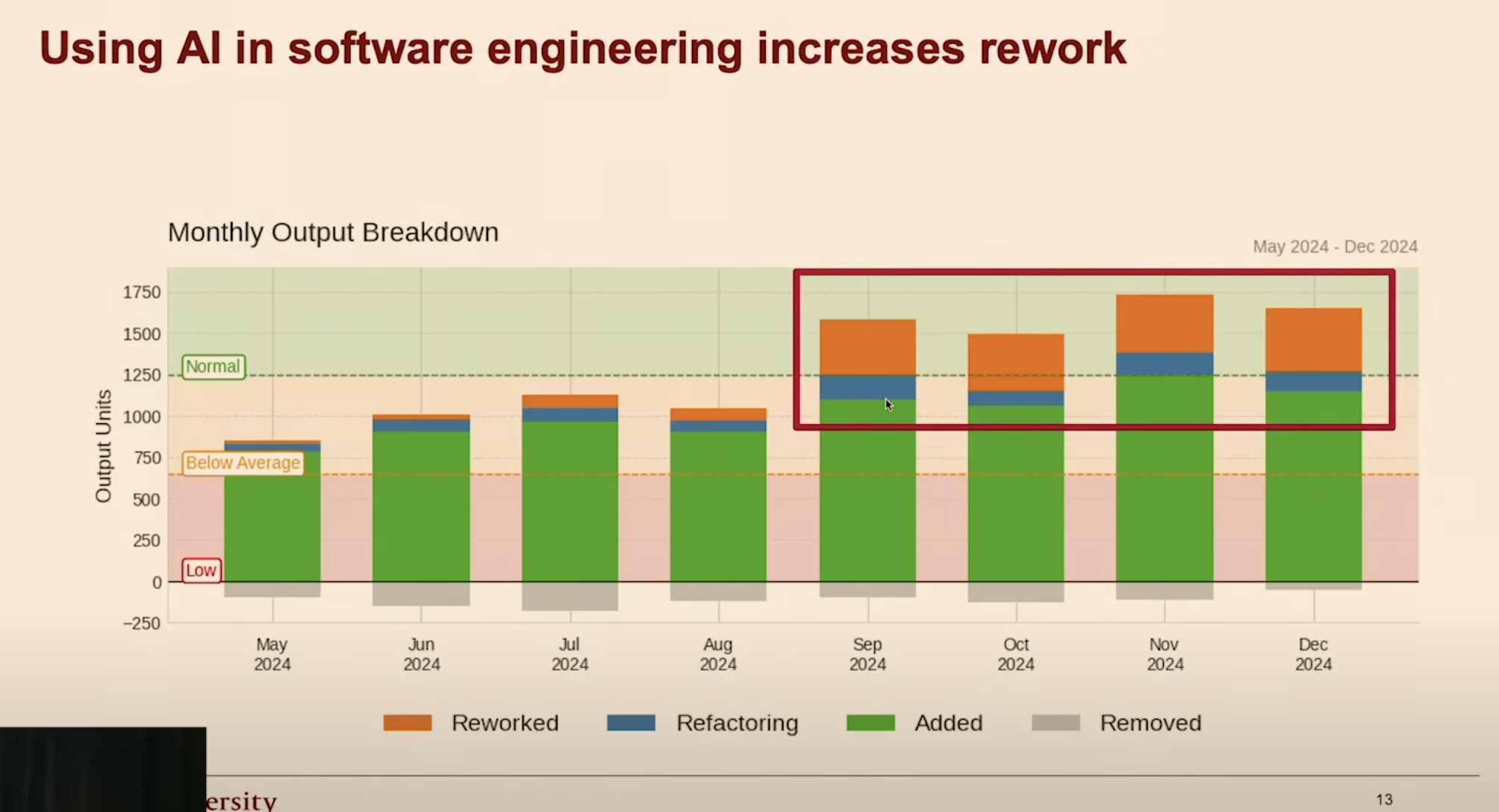 Monthly output breakdown: AI adoption without measurement leads to increased rework. Source: HumanLayer, Advanced Context Engineering for Coding Agents.
Monthly output breakdown: AI adoption without measurement leads to increased rework. Source: HumanLayer, Advanced Context Engineering for Coding Agents.
Claude Code has built-in OpenTelemetry support:
CLAUDE_CODE_ENABLE_TELEMETRY=1 \
OTEL_METRICS_EXPORTER=otlp \
OTEL_TRACES_EXPORTER=otlp
Session-level observability, LLM-as-Judge quality scoring, cost tracking, and tool use analysis are all available natively. The article’s “before and after” anecdote is not a substitute for instrumented measurement, and the platform now provides the infrastructure for instrumented measurement.
Why This Rate of Change Matters for Practitioners
A developer who configures Claude Code today using this article as their primary reference will:
- Miss the hooks system entirely — the primary mechanism for automated enforcement and session-level quality control
- Maintain a manual
claude.mdritual for memory that the platform now handles automatically - Run a Sequential Thinking MCP for reasoning capability that is already native to the model at
effortLevel: "high" - Configure MCP per-developer via CLI rather than via committed
.mcp.jsonshared across the team - Have no observability into session quality, cost, or model behavior over time
- Trust a performance claim that has no measurable basis
This is not a critique of the author. It is a critique of what it means to rely on any single blog post — however competently written — as a complete configuration reference for a platform that ships continuously.
What Still Holds
The problem framing is durable. Without persistent context, Claude produces generic outputs that ignore project conventions. That was true in early 2025 and is still true in 2026. The solution architecture has matured substantially, but the diagnosis remains correct.
The planning-mode-before-coding recommendation is sound and matches official best practice. Working through scope and requirements in plan mode (Shift+Tab) before allowing execution reduces rework across the board.
MCP as a mechanism for injecting external, real-time context is correct. The specific choice of Context7 for library documentation is still legitimate — fetching current library docs at query time is meaningfully better than relying on training data. The implementation details (transport, project-scope configuration) need updating; the strategy does not.
Use this article for:
- Understanding what a reasonable first-month Claude Code setup looks like
- Validating that MCP-based context injection is a real and useful pattern
- Introducing planning mode to a team that is not using it
Do not rely on it for:
- Hooks configuration or automated enforcement
- Team-scale MCP setup and permissions management
- Memory architecture beyond a simple project context file
- Reasoning depth controls or extended thinking configuration
- Any observability or quality measurement
The Broader Implication
Neural network research has an 18–24 month half-life on specific methods. Developer platform guidance appears to have closer to a 12-month half-life — and for actively-shipped CLIs with continuous delivery, possibly shorter.
The asymmetry has practical consequences for how teams structure their knowledge management:
- Problem framing (why context loss produces generic outputs, why retrieval helps, why planning reduces rework) — treat as durable, review annually
- Platform feature surface (hooks, settings, memory architecture, agent system) — treat as perishable; validate against official docs before any new team onboarding
- Specific tool and MCP recommendations — verify transport, configuration pattern, and whether the use case has been absorbed natively before deploying
The Marshall article is not stale because it was wrong. It is stale because Anthropic shipped faster than a personal blog can follow.
What to Do Next
The observability gap identified here is not unique to Claude Code configuration. It is representative of a broader pattern in how organizations adopt AI tooling: capability first, measurement never. A team that cannot instrument its AI workflows cannot tell whether those workflows are improving, regressing, or producing the outputs they think they are.
Proactive, at-scale measurement of AI inputs and outputs — before problems surface in production — is the practical counterpart to the audit framing above. Why AI measurement matters, and why most teams avoid it is a useful starting point for teams ready to move from configuration to accountability.
For organizations working to filter signal from noise across their AI tooling stack, Integrity Studio works specifically on that problem.
References
Audited Article
- Robert Marshall, Turning Claude Code into a Development Powerhouse
Claude Code Documentation (March 2026)
- Anthropic, Claude Code Overview
- Anthropic, Hooks
- Anthropic, Memory
- Anthropic, MCP
- Anthropic, Settings
CodeRabbit, State of AI vs. Human Code Generation Report. ↩
Cortex, 2026 Engineering Benchmark Report (2026). ↩
HumanLayer, Advanced Context Engineering for Coding Agents (2025). ↩